Introduction
Web Scraping is quite an interesting and powerful tool or skill to have in a Programmer's toolkit. It helps in analyzing data and getting some information in various formats. Web Scraping is a process in which a user fetches a website's content using some pattern in those HTML tags and the desired content to be fetched or scraped.
For this article, we aim to fetch the meaning of a word entered by the user from the dictionary.com website. We need to print just the meaning of the word from the HTML tags in it. We must have a good understanding of HTML and some basic Linux tools such as cURL, grep, sed, and others for doing all of these.
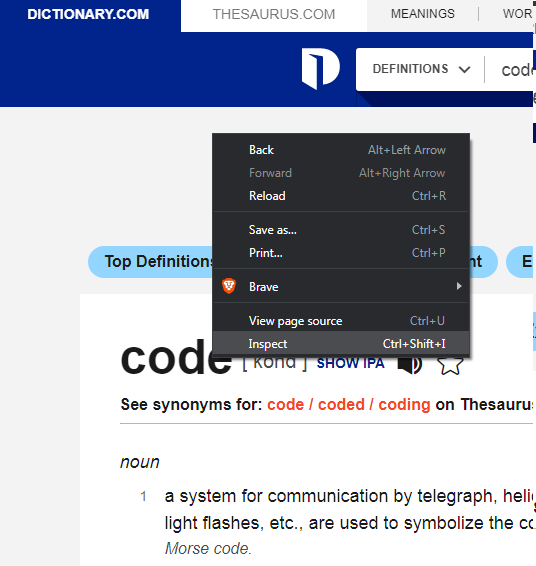
Inspecting the Target Website
To begin with, scrapping the website, first, it is absolutely important to inspect the website and view its source code. For that, we can make use of Inspect tool in our Browsers. Just Right-click on the website you are viewing or the website for scraping, a list of options appears in front of you. You have to select Inspect option( also Shift + Ctrl + I), this will open a side window with a plethora of options. You simply have to select Elements from the top of the menus. The code that you will see is the source code of the website. No, don't think you can change the content of the website from here :)
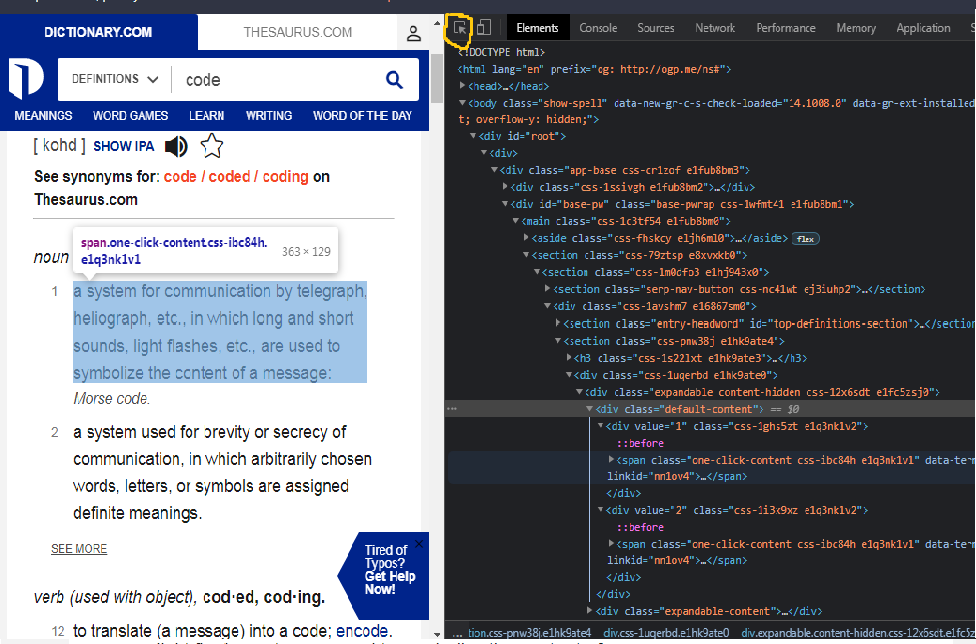 Inspect Tool in the browser.
Inspect Tool in the browser.
Now we have to analyze the website with the content which we want to scrape. You can go on for clicking the select the element in the page to inspect it option or icon in the top left-hand side corner. This will allow you to inspect the particular element that you selected on the webpage. You can now see the element tag, id, class, and other attributes required to fetch the element's content.
Selecting the particular element from the website to view the source code.
Accessing the website from the Command line/terminal
Now the website structure is being understood we can actually move to scrap it. For that, we need to have the web site's content on our local machine. First of all, we need to access the website from elsewhere not from the browser, because you cannot copy-paste content from there. So let's use Command Line here. We have a popular tool known as cURL, which stands for client URL. The tool fetches the contents of the provided URL. It also has several parameters or arguments that can be used to modify its output. We can use the command
curl -o meaning.txt https://www.dictionary.com/browse/computer#
The above command fetches the HTML page for the word Computer, it could be any word you might be searching for.
Understanding the Website Structure.
Here comes the time to explain the structure of dictionary.com. When you search a word on the website(dictionary.com), you are routed to /browse which then fetches the word for you and defaults you to the /browse/word# (the word can be any word you searched). The curl command dumps the output in the meaning.txt or any specified file. If you see the contents of the file, it is the same as on the web. So we are going to store the meaning of the searched word in the meaning.txt file, you can customize the name and command however you like.
Voila! you successfully scraped a webpage. Now the next target is to filter the webpage content.
Filtering Content from Website local file
Now we have the content of the webpage on our local machine, we need to search or filter out the useful content and remove the unwanted tags and elements. For that, we can use commands such as grep and sed.
Finding Tags to Extract content.
We need to find patterns and similarities in the tags that contain the text of the meaning of the specified word. From the analysis of the webpage, we see that the element <span class="one-click-content css-nnyc96 e1q3nk1v1"> contains the actual meaning. We just need the basic meaning, we may not need examples and long lengthy definitions on our Terminal, So we will go with filtering out the span tag with a class called one-click-content css-nnyc96 e1q3nk1v1. To do that we can use the grep command, which can print the text or line matching the specified expression or text. Here we need the span element with the particular class name so we will use regular expressions to find it more effectively.
grep -oP '(?<=).*?(?=)' meaning.txt >temp.txt
Using GREP command to filter.
The above command will search and return only lines that are contained in the span tags with that particular class name from the meaning.txt file which we appended to fill the webpage's source code. The -oP are the arguments that return Only the matching cases and -P the coming expression is a Perl Regex. The command will return everything in between those tags. Finally, we are storing the result or output in temp.txt.
Now, if you think we are done, then it's wrong, the webpage can have internal or external links embedded inside of the elements as well, so we need to again filter out the HTML tags from the temp.txt file. For that, we will introduce another tool to filter text called sed or Stream editor. This tool allows us to filter the stream field and print or store the outcome. The following code will remove the HTML tags from the scrapped text.
Using SED command to remove embedded
sed -i 's/<[^>]*>//g' temp.txt >meaning.txt
The above command filters the text and removes the HTML tags from the temp.txt file using regular expressions. The -i command allows us to store the output in a file meaning.txt. We have used Regex to remove <> tags from the file and hence anything in between these is also removed and we get the only pure text but it may also contain special characters and symbols. To remove that we'll again use grep and filter the fine meaning in our file.
Removing Special Characters from the Content using GREP commands.
grep -v '^\s*$\|^\s*\#' temp.txt >meaning.txt
Now from the above command removes the special characters such as $,#, and others from the temp.txt file. We finally store everything filtered in the meaning.txt file. If you understood till here, the next concrete step will be super easy for you, as we will assemble everything here in a shell script.
Making the Shell Script
#!/bin/bash
read -p "Enter the word to find meaning : " word
output="meaning.txt"
url="https://www.dictionary.com/browse/$word#"
curl -o $output $url
clear
grep -oP '(?<=).*?(?=)' $output >temp.txt
sed -i 's/<[^>]*>//g' temp.txt >$output
grep -v '^\s*$\|^\s*\#' temp.txt >$output
echo "$word"
while read meaning
do
echo $meaning
done < $output
We can clearly see most of the commands are the same, but some have been modified to avoid repetition and automation. Firstly, I have taken user input of word from the user and stored it in with an appropriate variable name. Next, I have created another variable to store the file name in which we are going to store the meaning of the word, Also a variable for the URL of the website we are searching for. We have used a variable to access the required URL. Then we invoke cURL to the file which we want to store using the variable we created and the URL variable So creating variables makes our script quite easy to manage and also it improves the readability of the script.
Updating cURL command
We can also update the curl command by adding "&> /dev/null" this will dump the curl output of network analysis. So we will only get the output of the meaning.txt file. It is optional to add the following into your code as it depends on the operating system so we can optionally use clear command to wipe out the curl output.
Printing the output file line by line.
To print the meaning in the output file, we need to print each line separately as the meanings are distinct. Therefore, we will use a while loop with the output file and echo the line variable we have used as the loop iterator.
Script Screenshots:
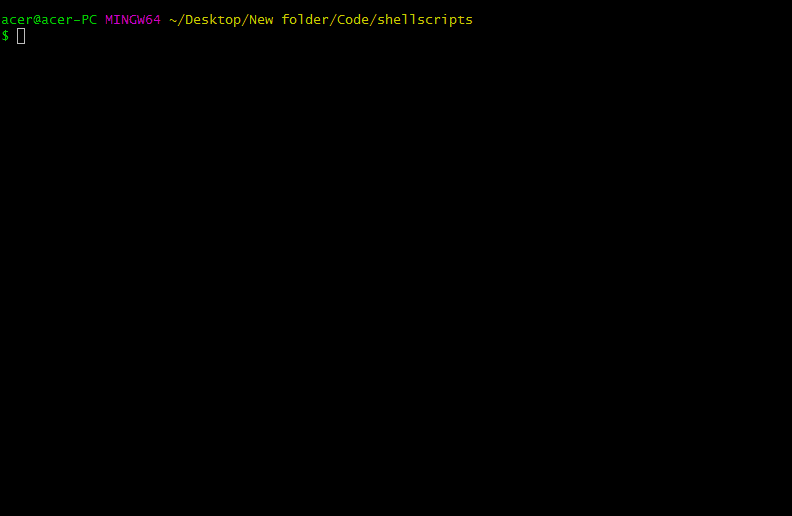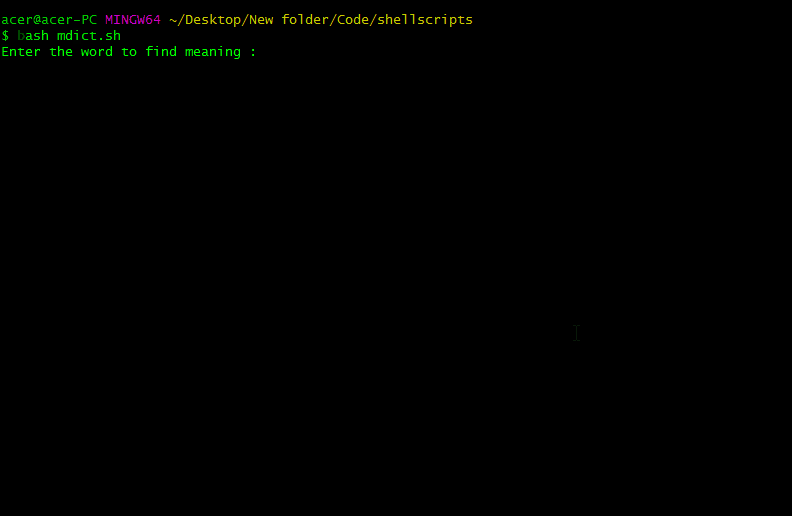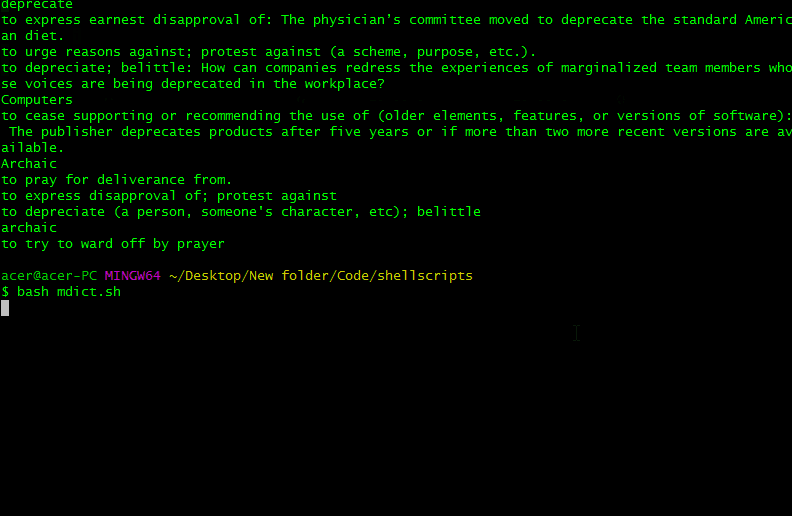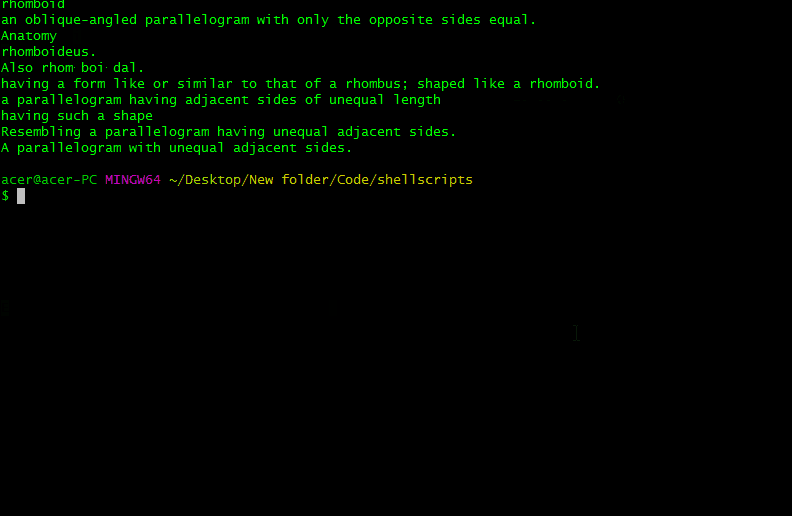
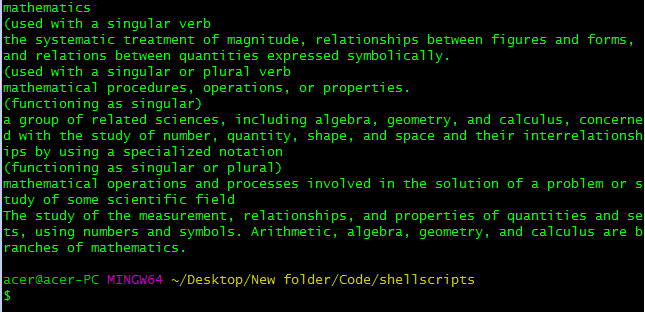
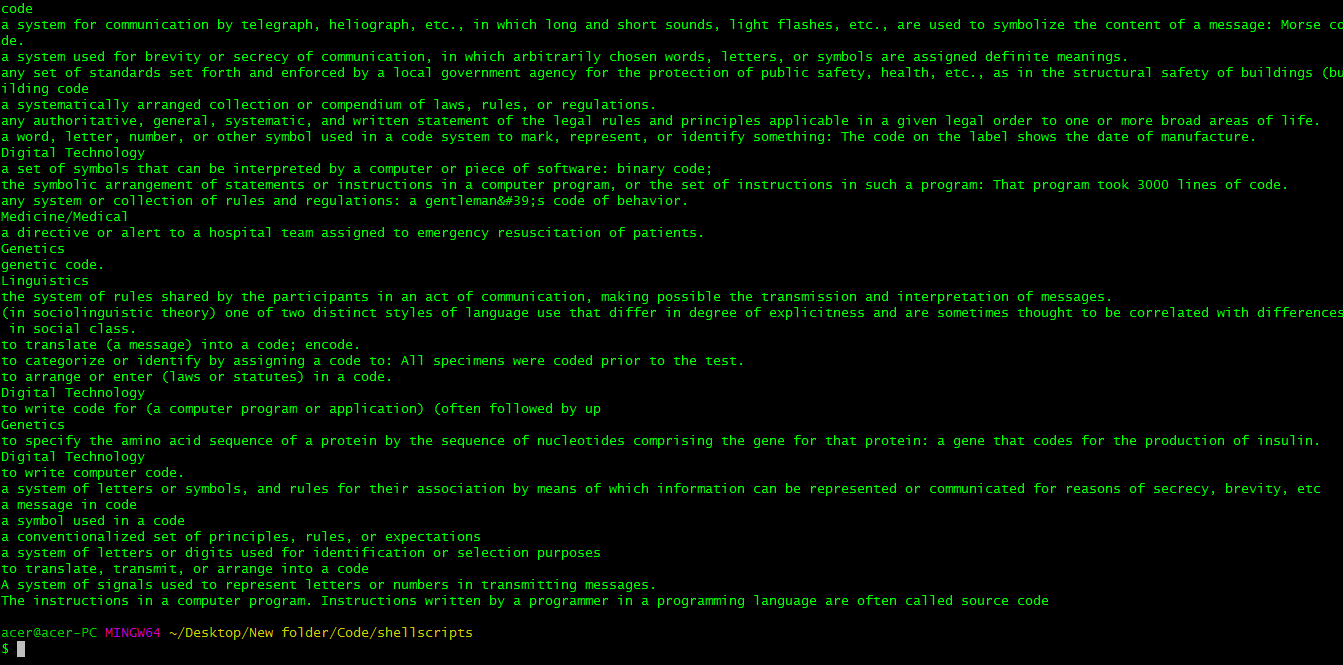

Output Conclusion
From the above output, we have scrapped the meaning of the word Mathematics, code, and python. It works only for the words which are on the dictionary.com website. We have successfully made a scrapper that scraps the meaning of the input word from the dictionary.com website,
Appropriate use of Web-Scrapping.
We must be careful and not scrape any website without reading its privacy policy. If they allow scraping from their website, then only you should scrape the content and not use it for any monetization of the content. This was just used for demonstrating some idea about web scrapping using BASH and just meant for teaching purposes.
Therefore, it is quite easy to scrape the website's content especially if you find any patterns in the code structure. We were able to make a script that can print the meaning of the input word from the base of the website dictionary.com.
We can see how Bash can be powerful in terms of web scrapping. I hope you found this interesting and inspiring. Thank you for reading. Happy Coding :)