Introduction
We all hear about terms like Machine Learning, Artificial Intelligence, and others, but what do they actually mean and why do you need to care about these as a developer. This won't be a perfect guide in terms of experience but surely enough to get anyone through the basics of Machine Learning.
This is not the kind of article I write but, having such challenges can help me become a better technical writer, this is the challenge put forward in the Hashnode Bootcamp 4 to get out of my comfort zone. Here's my take on what I know about Machine Learning till now (P.S. Half of the stuff I discovered and re-learned during writing).
What is Machine Learning?
Machine Learning is a technique in software development to predict and react to the inputs without being explicitly programmed or written. We can use the if-else condition till a point in time, after seeing real-world examples like customer service, driving, playing games(chess, checkers, etc), image prediction, and so on. You can't write code for every single case of these applications, So that is where we see Artificial Intelligence.
Artificial Intelligence is a process of simulating human-like behavior into computers /robots/ electronic systems.
These are two quite similar terms(A.I., M.L.) but they have their own differences. Let's look at those differences:
-
Artificial Intelligence is a technology that enables computer systems to act and decide like humans.
-
Machine Learning is a process of extracting data and learning from the past experience or outcomes from that data.
Machine learning is actually a subset of AI. Machine learning actually is about training the computer system about an outcome using the data feed into it. We will actually look at the detailed process about it in the next few sections.
The Process of Machine Learning
The first step should be to choose an idea or a goal that you would like to make the system predict or output the results.
- Data Gathering
- Filtering Data
- Selecting an Algorithm
- Training the system
- Verifying and Evaluation of Training
- Improving and Deploying the Model
Let's take the example of classifying a picture as either dog or cat.
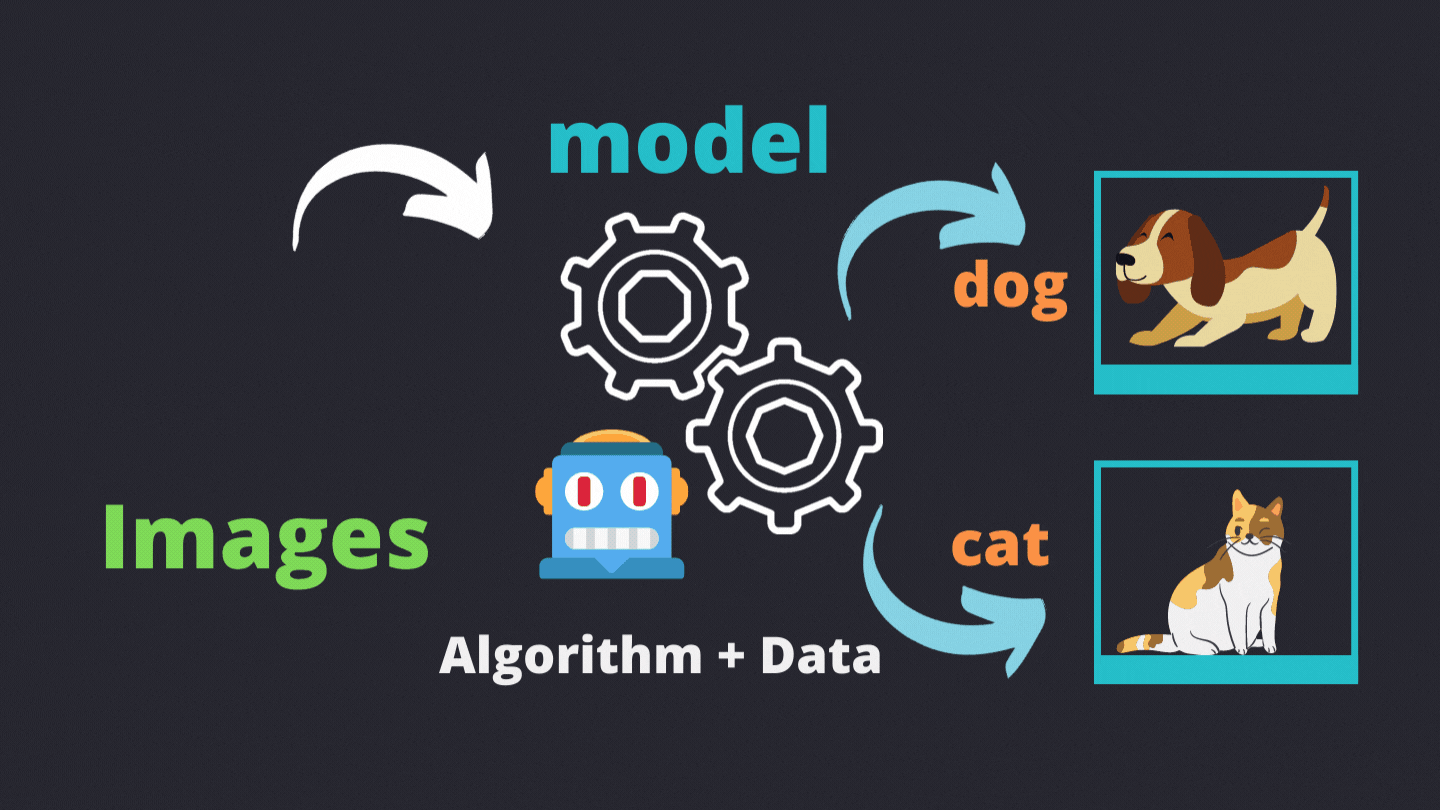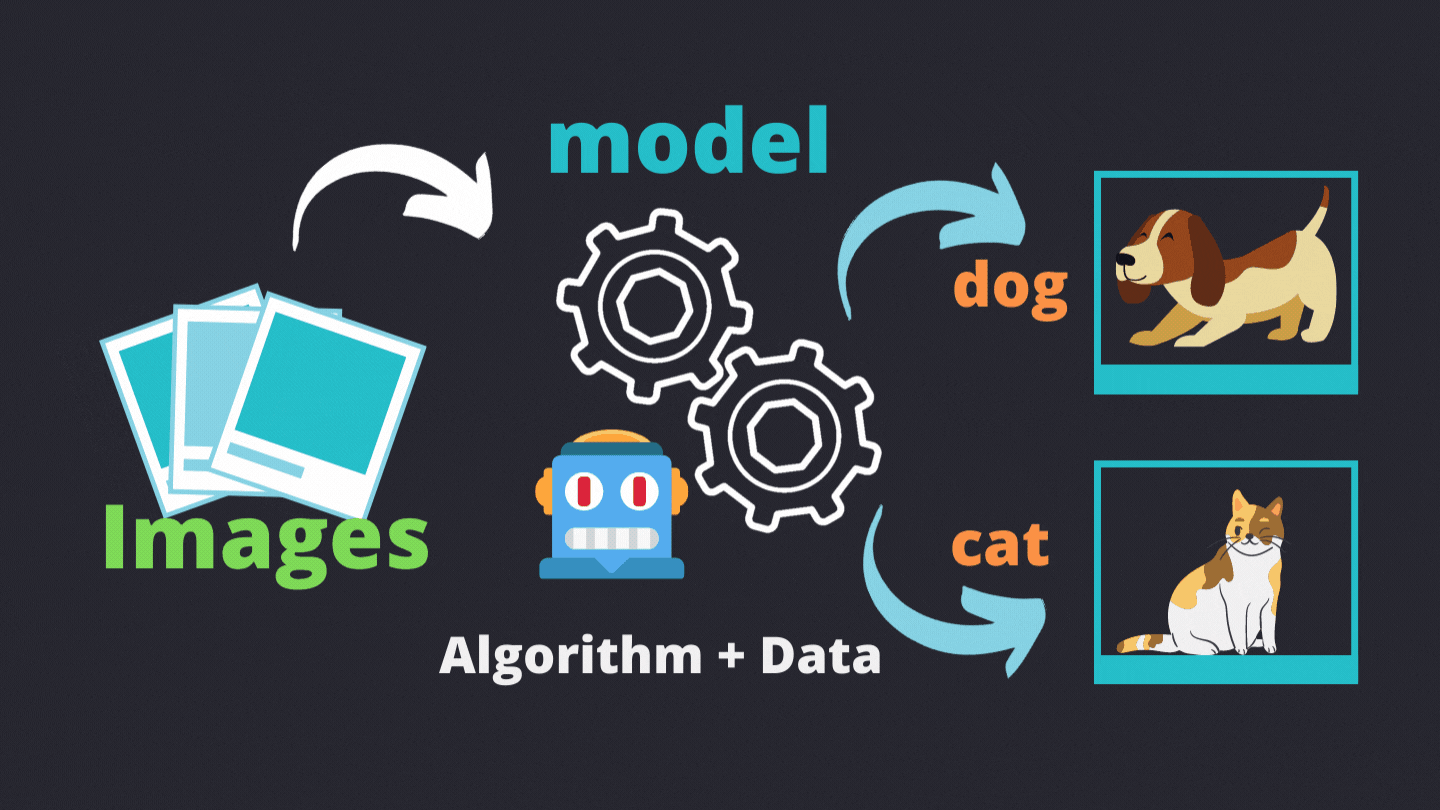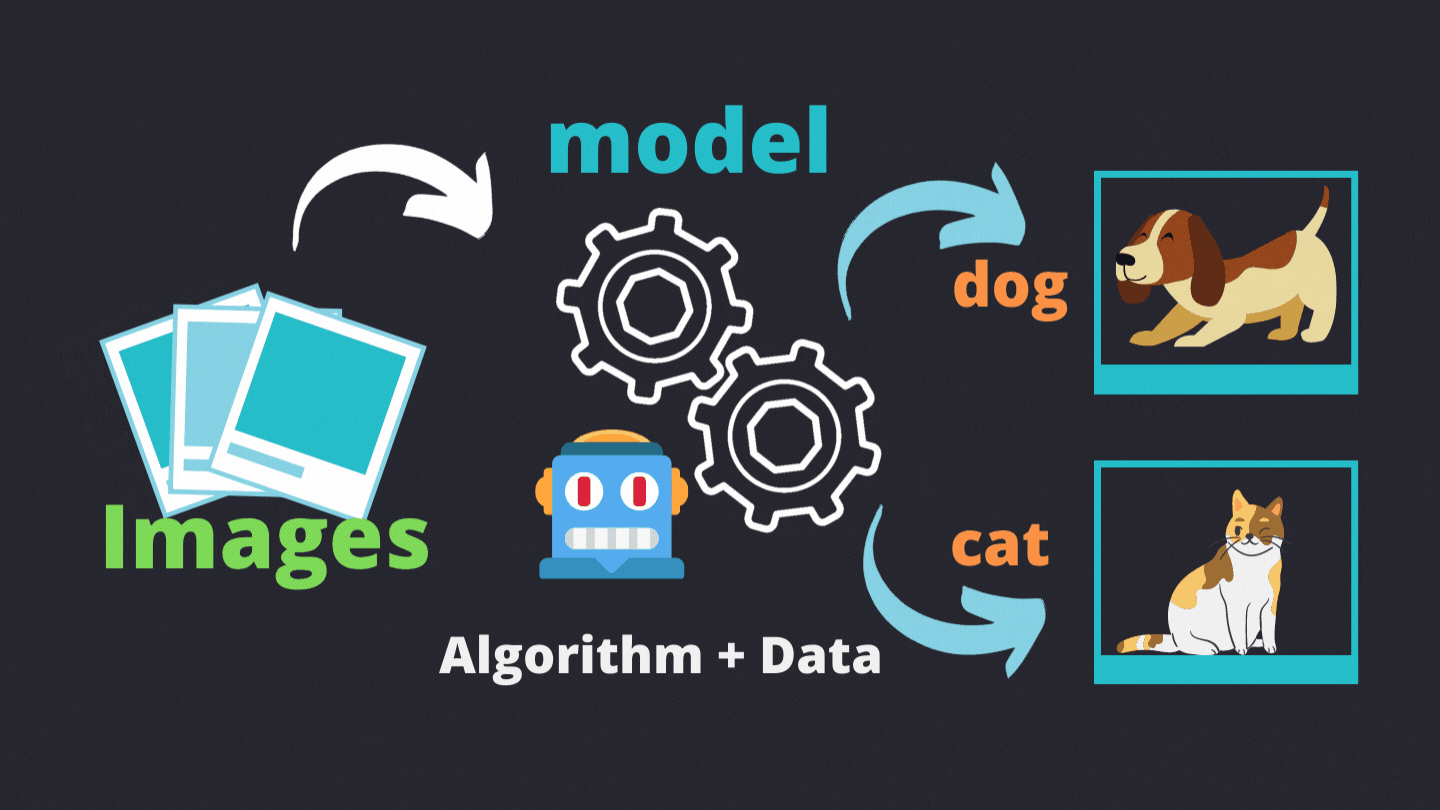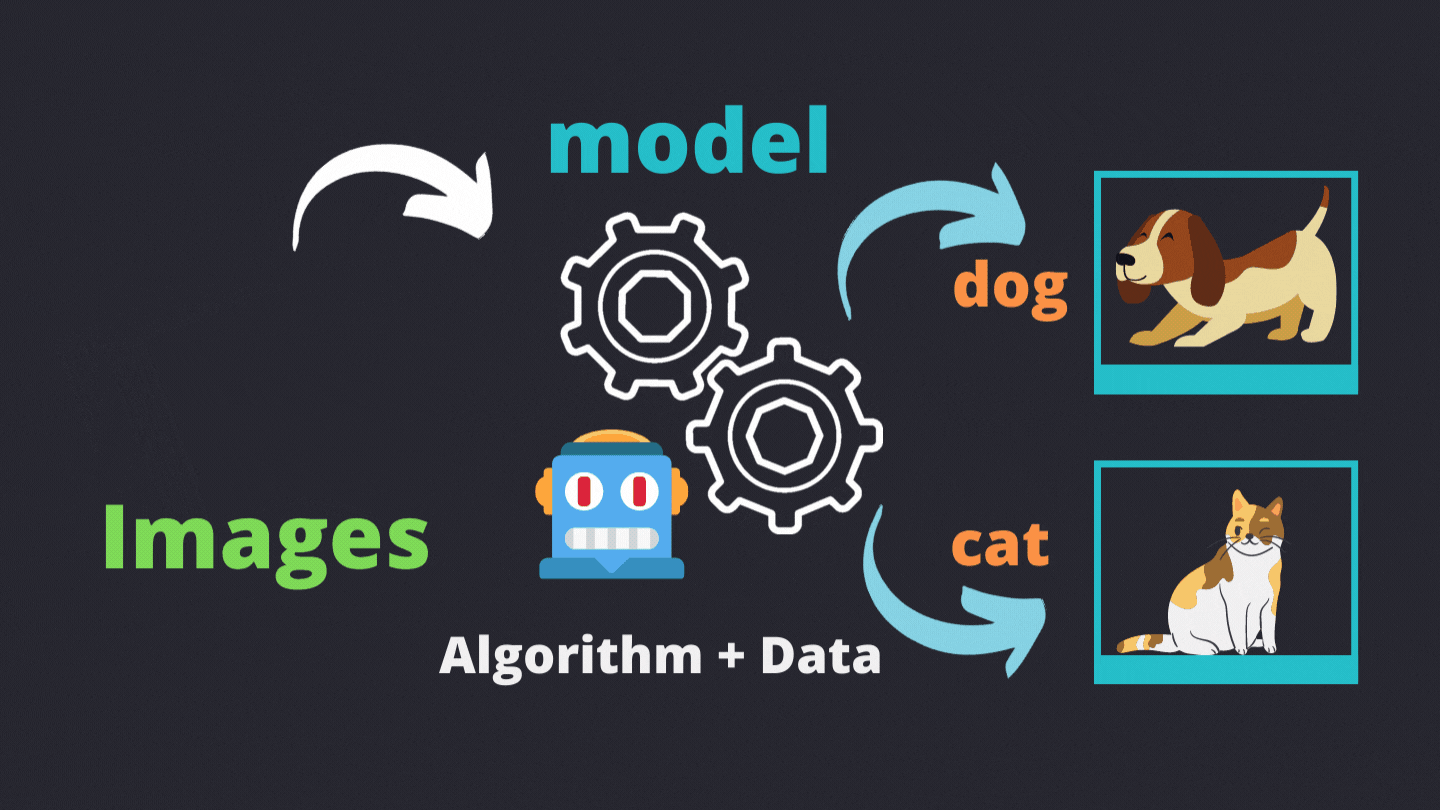
1. Data Gathering
We can now move on to collecting the medium of data that will be used by our system to get the desired outcome, it might be to predict something, classify certain things, take decisions, etc.
In our example, as we want to classify an image into either a dog or a cat is classifying things from the given data set. For that, we will require images that depict this constraint. We can use our personal data, public data and from other sources, you would like to get your hands on.
These are some of the popular places to get data publicly:
2. Filtering Data
After you have collected the data from some sources, you will notice that it is not perfect as per your needs. And to be honest, there is no dataset that is perfect for your requirements, because otherwise there will be a ton of data to work with, it might be inefficient for humans to create and sort out from that data. So we may have to do it manually or take help from a data scientist.
But if you are just learning, it will be helpful for you to filter and clean the data yourself. There will be things in the data sets missing or there will be unwanted things in it. This is a critical step that everyone tends to ignore but at the end of the day, spend about 80% of the time unknowingly. This is quite an important step as it decides the efficiency of the model you will have made.
- Remove/Fill in the rows which are empty.
- Remove the columns which are not related to your objective.
- Fix certain wrong or inconsistent data.
Group data as Training and Testing
After the procedure has been applied, you can now separate the data set as Training and Testing Data. You have to create two datasets from one, the prior for training and the latter for testing the model system after evaluating the tests.
For our example, we have to separate the images which will be relatively easier to distinguish in the training data, and the tough ones for the testing data as it will challenge the model appropriately.
3. Selecting an Algorithm
Now, this is again an important step as it will make your project's backbone. This will be the algorithm that will identify, predict or decide on the outcomes from the data given to it.
We have the following types of algorithms
- Linear Regression
- Logistic Regression
- Decision Tree
- Artificial Neural Network
- k-Nearest Neighbors (KNN)
- k-Means
You can choose any one of the above or find other types which will be more or less based on these algorithms. This algorithm will be decided by the outcomes you want, for example, whether you have to predict, classify, recommend, cluster, etc. the outcome from the given data. Different algorithms have different complexity as they have a completely different approaches.
You can research this more and find more about which will be suitable for your objectives or application.
Now an important topic that is misleading, Model is the program that will work with the data in association with the algorithm and output the actual objective. Model is not the algorithm but it works with the chosen algorithm and processes the actual learning in machine learning.
So,
Model = Algorithm + Data
The model will actually process the data according to the algorithm given and fill in the objectives may they be classifying or predicting.
4. Training the system
Training is a step that is very interesting as it involves actually testing the model and it's really fun. We provide the model the training data that we segregated while filtering the data. In this process we try to minimize the loss by making changes to the algorithm, fix some data set or bring in some additional dataset as per needs and again evaluate the results. This is a loop called model fitting.
This step depends on the learning into consideration, whether you want to provide any supervision or not.
5. Verifying and Evaluation of Training
This is a part of model fitting as it is the part of the loop which allows us to evaluate and verify the model. We can evaluate the model based on its accuracy, precision, labels, etc. So based on those parameters we should be able to decide its complexity and performance.
These are important aspects to consider in evaluating the model.
- Accuracy
- Precision
- Recall
You can get the details of the mathematics and logic involved in evaluating the model with some references like:
6. Improving and Deploying the Model
This might be the final step generally but it depends on the project, there are certain aspects that need to be taken care of like:
- Creating an API endpoint
- Analysis and Visualization integration with client-side (web/android/ios/desktop app)
- Creating a Pipeline for data input and output from the model.
There might be other options like CI/CD, Testing, feedback, and other production level details that need to be taken care of, you can read more about the deployment of machine learning models here.
You can learn about deploying an ML model for your learning and testing for free with the recommendations of FCC.
Different Types of Machine Learning
There are four basic types of Machine Learning :
1. Supervised Learning
In this type of ML, the model is given the labeled data in the training dataset and is evaluated. We provide both input and output to the model and hence it is supervised or tracked throughout the process.
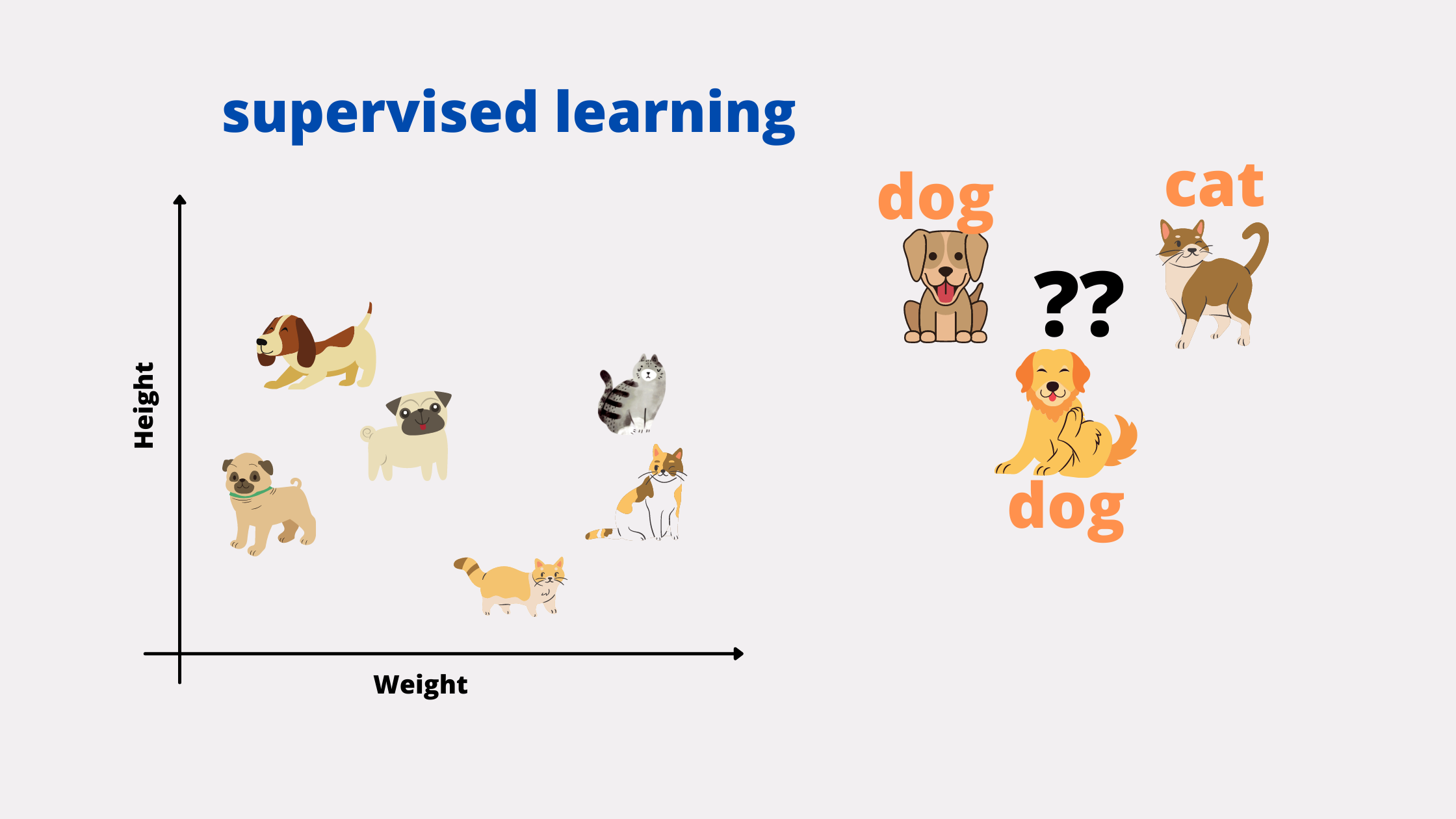
The above image is just for reference and not directly a model, height and weight can be a parameter to consider and are not only the thing to be considered her. It's just for making understand the concept of the learning process.
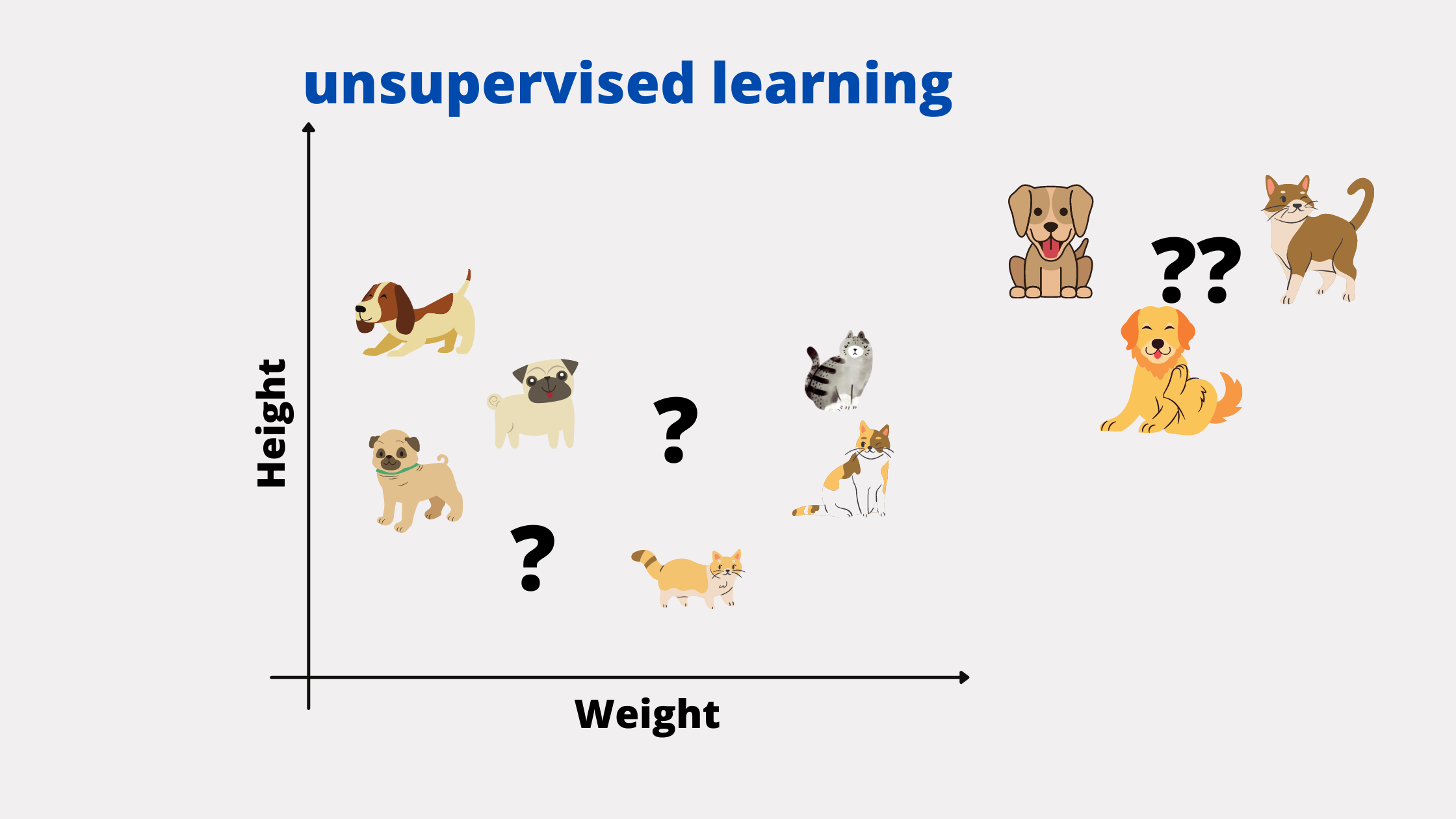
2. Unsupervised Learning
In this type of machine learning, the model is trained with unlabeled data. It is on the algorithm to actually see the pattern or logic in the dataset provided and give the output. The output will be known to the user but is not given to the model, hence called unsupervised learning.
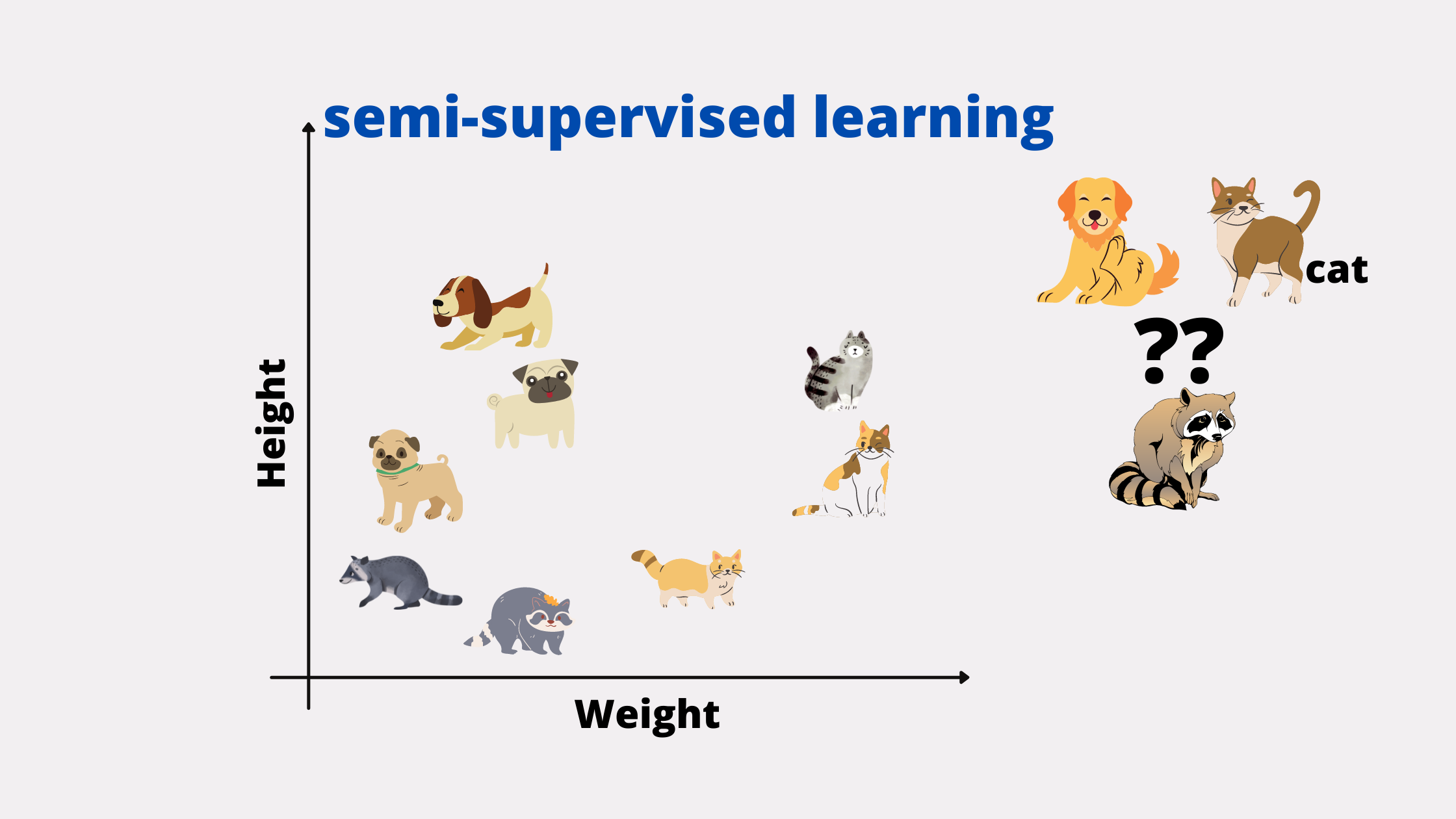
3. Semi-Supervised Learning
As the name suggests, it is a combination of both Supervised and Unsupervised learning. The dataset is given with the label but the model is also allowed to process its own label(kind of) into the output. Hence having the best of both worlds. There might be even some labeled and some unlabeled datasets as per the requirements of the application.
4. Reinforcement Learning
In reinforcement learning, the model learns from feedback. It might look similar to supervised learning but here the feedback might not be instant and hence causing delay and improper decision making from the model. Though it is used in many places, it is like the realistic learning behavior of humans depicted to computers with this learning system.
There are other types of learning systems as well but these are used quite commonly and are quite versatile as well.
Applications of Machine Learning
The applications of Machines Learning are all around you. Just look carefully, you would have even feedback on a model!
- Personal Assistants (Google Assistant/ Siri/ Alexa)
- Gmail Inbox filter.
- Youtube Video Recommendation system .
- Face recognition ( DeepFace )
- Product Recommendations.
- Self-Driving Cars( Tesla )
- Traffic Alerts (Google Map)
- Text Improvement (Grammarly)
This list is quite huge and is increasing every day with new technologies and growing popularity.
Can GitHub Copilot take away developers' jobs?
This just doesn't focus on developers, it's every human's job on target this day but really? Is it a matter of concern? I don't think so, because,
the number of jobs lost = the number of jobs given.
There will be a need for humans in some or the other way, remember a computer cannot is not smart like humans, surely it has improved from what we thought a couple of years ago. But who discovered this? HUMANS.
Yes, Machine Learning is quite a powerful technique but humans will remain the essence in the world. It will be dependent on humans how we treat the models and use them to our and nature's advantage and not use them against nature to face the consequences later.
Conclusion
Ok, so from this big article, we can summarize the Machine Learning concept.
Machine learning is a program that has a dataset and algorithm along with the model for the objective, we train the model as per the requirements and objectives with our dataset.
We were able to understand some common processes involved in Machine Learning. We even discussed the applications and the state of Machine Learning in today's world. I hope you found this article helpful. Thank you for reading. Happy Coding :)